The count hides the problem. Every citation came from a query that already named the brand. On the queries where new buyers discover, it scored zero.
How we ran it
We picked six high-intent queries a real shopper would type when buying in this category — a mix of discovery queries (where a buyer doesn't yet know which brand they want) and named queries (where they already do). We ran them live in Perplexity with web search on, and scored each one simply: is the brand cited, or not? Then we cross-checked the two key discovery queries in ChatGPT.
No personalization, no logged-in history, no cherry-picking. Just the answer a cold shopper would actually see.
What the six queries returned
| Query (real buyer intent) | Brand | Who carried the answer |
|---|---|---|
| "best [category] brands 2026" | Cited · 3rd | A single magazine listicle |
| "is [brand] worth it" | Cited · positive | Two third-party review sites |
| "[brand] vs [category leader]" | Present | AI calls the leader the "default" |
| "best [category] for screen time & blue light" | Invisible | Generic health sites; no brand named |
| "things to know before buying [category]" | Absent | Generic educational sources |
| "alternatives to [category leader]" | Invisible | Six rival brands listed — this one absent |
Read the pattern, not the score. The three queries where the brand appears are the three where the shopper already named it or named its direct rival. The three where it's invisible are the pure discovery queries — exactly where a brand needs to win to grow.
The receipts
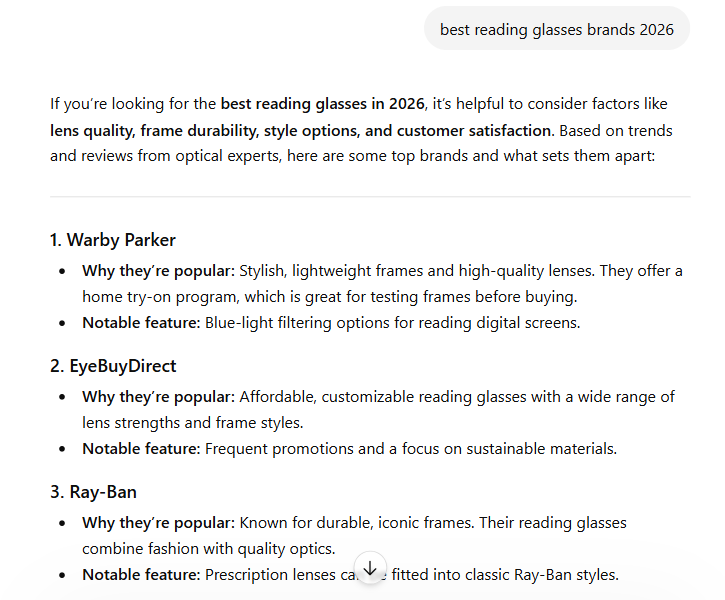
Here's the category discovery query in ChatGPT — "best reading glasses brands 2026." It confidently recommends three competitors. The brand we audited isn't mentioned at all.
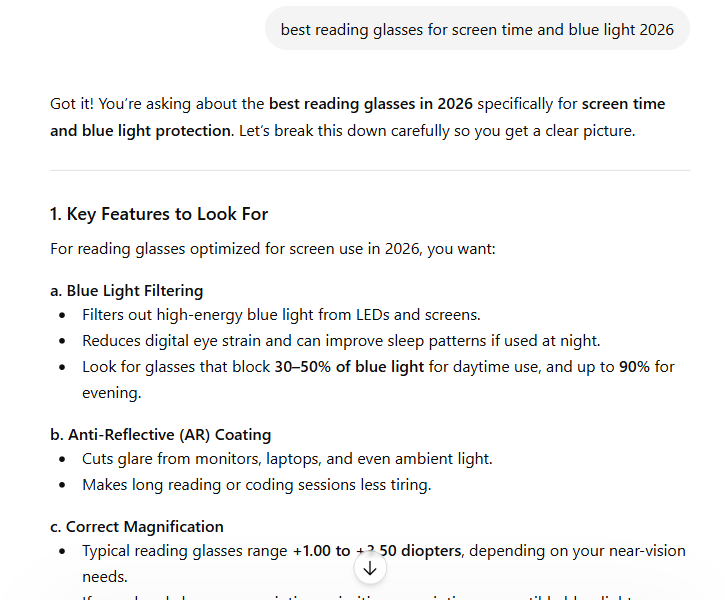
And here's the query in the brand's own differentiator — blue-light readers for screen time. The answer is entirely generic. No brand is named at all — not the leaders, and not the one brand whose whole pitch is this exact use case.
The three findings that matter
1. Single-source dependency
In the broad category query, the brand appears only because one magazine article happens to list it. Remove that single source and its category visibility largely disappears. Visibility shouldn't hang on one editor's choice.
2. Invisible in its own category — the expensive one
The "blue-light / screen-time readers" query is the exact space this brand differentiates on. The AI answer names zero brands and cites generic optometry content. A high-intent buyer standing in the brand's home turf never hears its name.
3. Absent where the rival's buyers look
"Alternatives to [the category leader]" returns six eyewear brands. This brand — a direct stylistic competitor — isn't one of them. Shoppers actively seeking an alternative are routed everywhere except here.
Why this happens
- Citation layer. The brand has no owned-source authority — AI engines won't quote its site, so visibility is hostage to whatever editorial happens to mention it.
- Technical layer (verified on a live product page). The good news: its product pages already carry solid baseline structured data — Product, Offer, Brand, and AggregateRating are all present. What's missing is the answer-shaped markup AI leans on hardest: Review schema and FAQ / Q&A schema. So the technical gap is narrow and fixable — not a rebuild.
- Content layer. No owned content ranks for the high-intent discovery queries it's losing. The answers exist — they're just written by other people.
What the gap costs
Buyers typing "best blue-light readers" or "alternatives to [the leader]" — precisely this brand's ideal customer — are handed competitors and generic retailers in the AI answer. That's discovery and revenue leaking to whoever the model cites, on the exact queries the brand should own.
The 90-day fix
| Phase | Work | What you'd see |
|---|---|---|
| Foundation · week 1 | Add the missing Review + FAQ/Q&A schema (the rest is already in place) so the site becomes a quotable source | Live in week 1 |
| Content · weeks 2–6 | Owned, answer-shaped content for the gap queries: blue-light readers, alternatives, comparisons | First movement ~day 30 |
| Seeding · weeks 4–10 | Multi-source third-party citations so visibility isn't hostage to one article | Compounding ~day 90 |
Realistic arc: foundation visible in week 1 → first signal around day 30 → compounding by day 90. AI search mechanics are real and they take time — we don't promise overnight, and you shouldn't trust anyone who does.
About this teardown. The audited brand's identity is withheld on purpose. Every query result shown is a real, unedited AI output captured in June 2026 — nothing is fabricated or estimated, and where an engine wasn't run we'd say so rather than guess. Competitor names appear only as the AI engines returned them; their inclusion is factual reporting of those results, not a claim by, or affiliation with, GeoNexa. This is the same evidence standard behind our own public 4/100 Case Study Zero.
Want this run on your store?
We'll run your brand through all five AI engines and send back where you're cited, where you're invisible, and the top three gaps to fix — straight to your inbox, no call required.
Get your free AI visibility audit →